
"Decoding Attention" Chapter 2 - Understanding Embedding and Linear layers

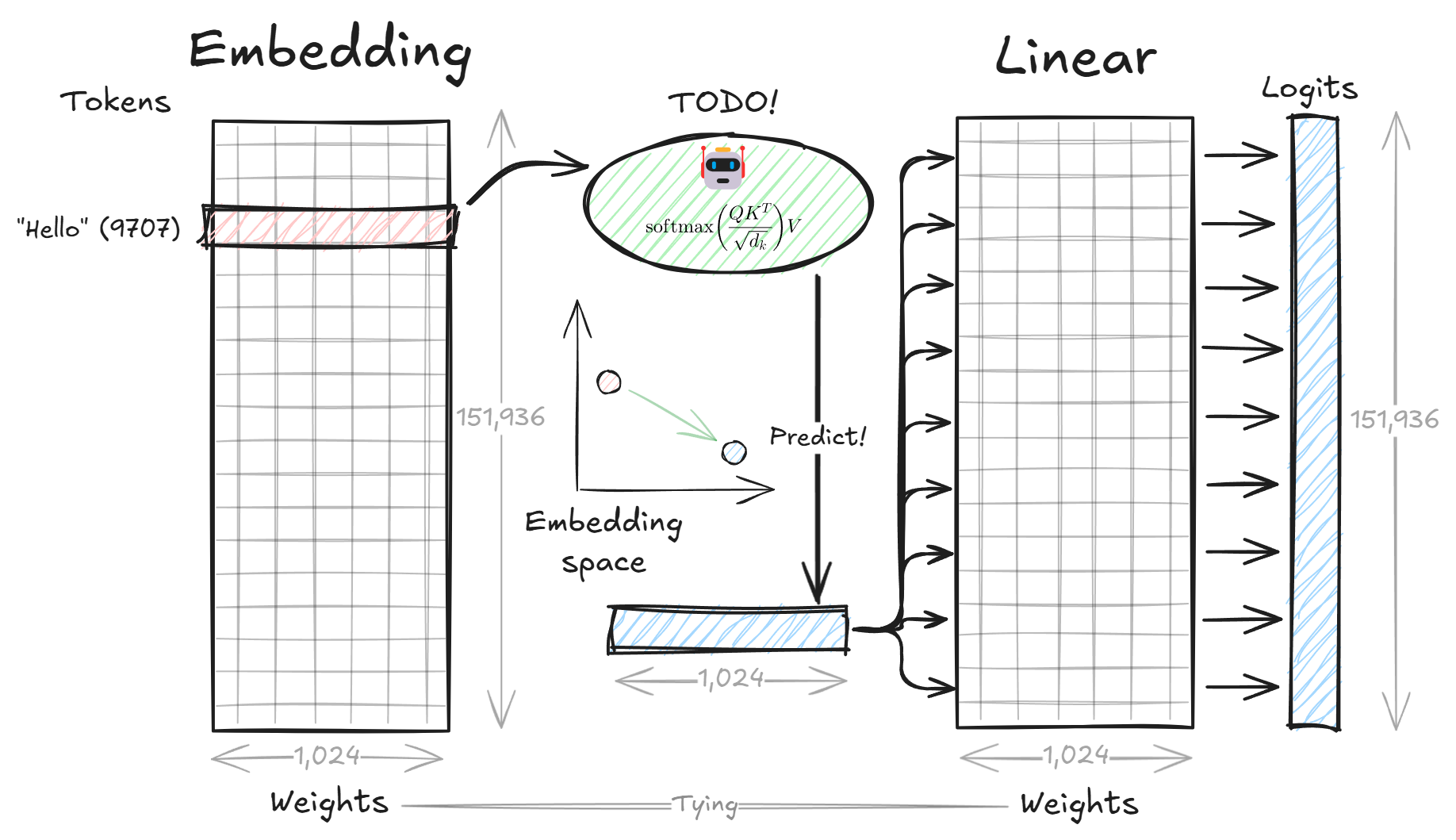
I’ve launched the chapter 2 of “Decoding Attention”. In this chapter, you’ll learn about the first and last layers of Transformer - Embedding and Linear.
The progress is good as I’ve completed my own Qwen3 implementation, thanks to Sebastian Raschka, PhD’s reference implementation.

I’ll keep working on “Decoding Attention”. The next chapter is the neural network and I’ll explain from the basic perceptron to Qwen3’s MLP.