
Ep 5: Cell-based Architecture 101 - Why?
Learn why Cell-based Architecture is needed even though cloud is designed for scalability and availability.

In the previous post, I’ve introduced two key problems that Cell-based Architecture solves:
Scalability
Availability
However, these are very common problems in any cloud system and there are tons of solutions/design addressing them already. Why do we need to solve them again?
In this second episode of “Cell-based Architecture 101“, I’d like to talk about the limitations of the existing solutions/design in cloud so that you would be able to understand why this new architecture is needed.

The series consists of 5 short posts:
Why is Cell-based Architecture needed? (this post)
How to implement Cell-based Architecture?
“Highly scalable and available” in cloud
Assuming you’ve already built or designed some application in cloud. You know one of the core values of cloud is the massive scalability because the cloud services are running on the hyperscale infrastructure. For example, an Amazon S3’s bucket can contain billions of objects or more. So, when you design an application using S3 bucket, you don’t have to worry about the maximum number of objects allowed in a bucket.
Another big benefit of cloud is the capability of highly available system design. Because of elasticity and physical distribution, you can build your system using multiple instances/availability-zones/regions to make it more available. For example, Amazon RDS offers multi-AZ failover so that a DB instance isn’t Single-Point-Of-Failure a.k.a. SPOF anymore. Like Netfilx, you can shift traffic across regions to avoid even single region failures.
Therefore, with such traits of cloud, your application is typically highly scalable and available out of the box. Let me introduce a very simple example here; A request/response system, ALB for load balancing, EC2 for application servers with Auto Scaling Group to scale in/out and RDS for database:
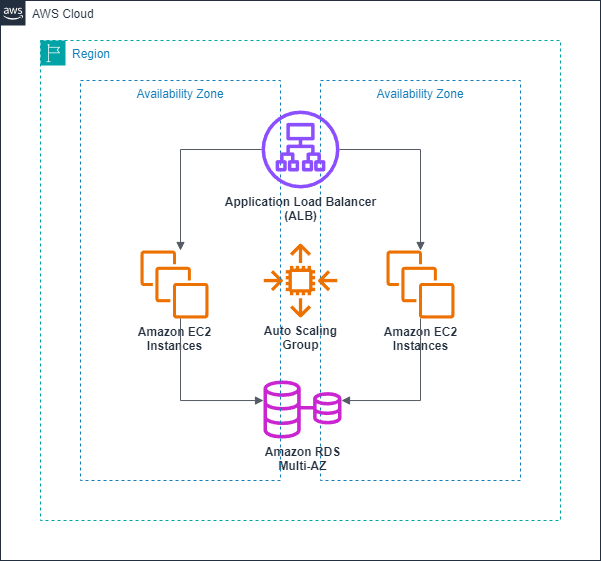
In this system, ALB, EC2 and RDS are deployed in multi-AZ. Therefore, it’s single-AZ failure tolerant. Also, ALB, EC2 and RDS can scale elastically so that it can support from 1 req/s to millions. No need to worry about scalability nor availability.
…Well, is this true? As you expect, it’s not 100% true. Let’s find some limitations in the next section.
Scalability of cloud
In the previous example, you’ve probably noticed that it has an obvious scalability bottleneck. RDS needs a single writer instance and it must have scalability limit because it’s a single machine so that CPU, memory, network or any other resource has its physical limitation1. That’s a super easy bottleneck, but is this the only one?
ALB is more scalable than RDS but it has some default quotas. Although most of them are adjustable, there is no guarantee that your limit increase requests are approved by AWS. Some might have actual hard limits internally so that you couldn’t exceed that hard limit. For example, the default quota for the number of certificates per ALB is 25. So, if this application provides a custom domain feature, one ALB can host up to just 25 custom domains until the limit increase request is approved2. The same logic can be applied to EC2 quota for the number of instances i.e. EC2 layer might not be scalable until limit increases even though you use Auto Scaling Group properly.
Lastly, even if your system doesn’t hit any service quotas and RDS writer can handle the volume of the requests, EC2 instance itself could hit some limit. For example, if you want to cache some metadata in-memory of your application running on EC2 instance, you need to be careful about the size of the metadata. Let’s say the metadata glows proportionally with the number of users and need to be cached in-memory on every instance to achieve the performance target. As you get more users, the metadata size increases and eventually could exhaust the physical memory space. The only solution here is scaling up all the instances but it’s not infinitely scalable as you already know.
In summary, the example system could have three types of scalability bottlenecks:
Single writer DB instance
Service quotas
Physical limit on every application server
You would argue that your system’s workload doesn’t require such high scalability and these are not critical. Yes, that’s true. However, once you want to accelerate the growth of your business, you could be easily blocked by these bottlenecks and take way longer time to re-architect everything to workaround them. Even worse, you might hit unknown limits whenever you scale more and they always annoy you.
Availability of cloud
How about availability? The example system uses multi-AZ architecture well, so single-AZ failure doesn’t mean 100% outage. It doesn’t look having any SPOF: ALB is distributed service and failures are handled by AWS under SLA, EC2 is a fleet of instances and instance failures are handled by Auto Scaling Group, RDS has auto failover.
Let me provide one extreme case. What would happen if you accidentally scaled Auto Scaling Group to zero instances? This could be done by just a single API call or console operation. Once it happened, this system would have no application server i.e. 100% outage. The similar event could happen on any cloud resources e.g. deleting RDS, updating Security group wrongly, etc.
The next case is already explained in the section of Scalability of cloud. Once RDS writer instance reaches the performance limit, it affects all the requests. If one EC2 instance exhausts all memory by the large metadata, the same issue happens on all EC2 instances. Any scalability related outage could be a full system outage.
The last case is more realistic and you’ve probably experienced already. That is one single bad deployment causing 100% outage. For example, if you automate DB schema migration in your deployment workflow but unfortunately you’ve deployed ALTER TABLE on a huge table requiring an exclusive lock. Until it finishes, all the DB queries using the table don’t work and it would mean 100% outage. Another example is a Black swan3; let’s say you deploy any new code to one instance first to make sure it’s safe to deploy. Unfortunately, a new code contains a bug that issues a super heavy and long running SELECT query only if it is used by just one customer who has some special condition. Once that customer hits the single instance, your DB becomes overwhelmed even though you deployed only one instance.
In summary, the example system could have 100% outage by three cases:
Accidental modifications of cloud resources
Scalability bottleneck
Bad deployment
You might think some of RDS related issues can be solved by using Serverless DB like DynamoDB, but the answer is no. Once you hit WCU/RCU limits, all the workloads are affected. Wrong UpdateTable or modifying IAM policies can be 100% outage. Although DynamoDB is highly distributed, scalable and available service, a single DynamoDB table is logically SPOF.
What’s next?
In this post, I’ve described several cases that the typical “highly scalable and available cloud system“ could be easily broken. These are actually very limited examples and there are millions of cases including unknown cases.
This is the nature of cloud. You can’t avoid “Everything fails all the time“. But, you do want to build scalable and available system in cloud. Cell-based Architecture is the state-of-the-art solution here. Now, you’re interested in Cell-based Architecture, aren’t you?
In the next post, I’m going to explain the basic concept of Cell-based Architecture and how it solves these scalability and availability issues.

Thank you for reading. If you’re interested in this series, please hit the “Like“ button and share this to any social media. I would be motivated more! Also, subscribe this magazine to receive the upcoming posts for this series!
Amazon Aurora Limitless Database is an interesting approach to make RDB scale out. PlanetScale is yet another solution and Vitess is an OSS project to achieve the same goal.
Although I don’t think they would like to support millions of certificates on a single ALB, I’m not sure whether they have a hard limit for this quota. If you’re keen on such higher quota, I would recommend you to talk with AWS Support or AWS Solutions Architect.
In Amazon/AWS, people typically call it “Poison pill“ but it doesn’t look popular outside Amazon/AWS.