
Ep 6: Cell-based Architecture 101 - What?
Learn three components of Cell-based Architecture and how they solve the problems.

In the last episode, I showed several cases where the simple cloud usage doesn’t enough to provide neither scalability nor availability. The key reasons are:
Scale is not manageable
Logical SPOF
Because you need to scale the only one stack of system to fit your business demand, you can’t control the size of users, resources, etc., that leads unknown scalability bottlenecks.
Also, no matter how each cloud service is designed as highly available as possible, a single resource can be a logical SPOF anytime and could down the entire system easily.
In this post, I’m going to introduce the key concepts of Cell-based Architecture and why they can address these issues.

The series consists of 5 short posts:
What is Cell-based Architecture? (this post)
How to implement Cell-based Architecture?
Cell
As I mentioned above, one of the key issues of the single stack system is unmanageable scale. If you can control the maximum size of the system e.g. the maximum number of users or resources, it’s much easier to manage the scalability of the system. For example, during a load testing, you don’t have to worry about too large scalability way above the maximum size and it should be a good coverage if you could address all the known scalability issues found by the load testing.
This limited-scale single application stack is called “Cell“. It’s manageable in terms of scale per cell. If you want to host more users/resources than the maximum size of one cell, you simply need to add more cells. For example, UserID 1-100 are hosted in Cell-0 and UserID 101-200 are hosted in Cell-1, and so forth. See the example below:

As you can see above, you manage two completely isolated systems, each has identical full stack architecture1 but stores completely different data set.
How about availability? Now, every layer is no more logical SPOF. If you have a super problematic user i.e. Black swan/Poison pill and your database is brown away, only one of cell is affected. That means the blast radius is 50% of the total users. In other words, if you have N cells, the blast radius is 1/N. This is also helpful when deploying a bad commit. With cells, you can deploy cell by cell and monitor after each deployment and block promotions when it’s bad. So, if there is a pretty bad deployment, the first deployed cell is the only victim i.e. 50% blast radius, again.
The other notes for cells are below. Some will be covered by the remaining series:
Running the same code
A cell isn’t a tailer-made solution per customer
Silo as much as possible
From top to bottom; ALB to RDS, even AWS account should be isolated per cell2
Typically, no direct communication between cells are allowed
Partitioning dimension differs case by case
Partition by user
Good when the number of resources per user is manageable
Partition by resource
Good when the number of resources per user is unmanageable
Heterogeneous size is acceptable
One cell could host only 1 user while others host 100s per cell because of single-tenant request or isolating noisy neighbors
Summary of Cell
Cell is a very simple but powerful concept. By just splitting your users or resources, you can solve both scalability and availability problems we talked so far. It’s so simple that any type of systems can be implemented as a cell. If you have a running application, that would be called as Cell-0 today and you can prepare Cell-1 tomorrow.
Cross-cell Data plane a.k.a. Routing layer
Although the concept of cell is simple, the reality isn’t. As you might notice, I haven’t talked about how to “route“ each user to the appropriate cell. This is the uniqueness of Cell-based Architecture.
You probably want to keep your system look non-cellular from the users’ perspective because it’s internal details. Another reason for that is you might migrate several users to the other cell, then they need to change their endpoint to the new cell unless some cross-cell layer exists. In the example below, “Routing layer“ is the component to dispatch users to the appropriate cells. I would call it Cross-cell Data plane but “Routing layer“ is more famous name:
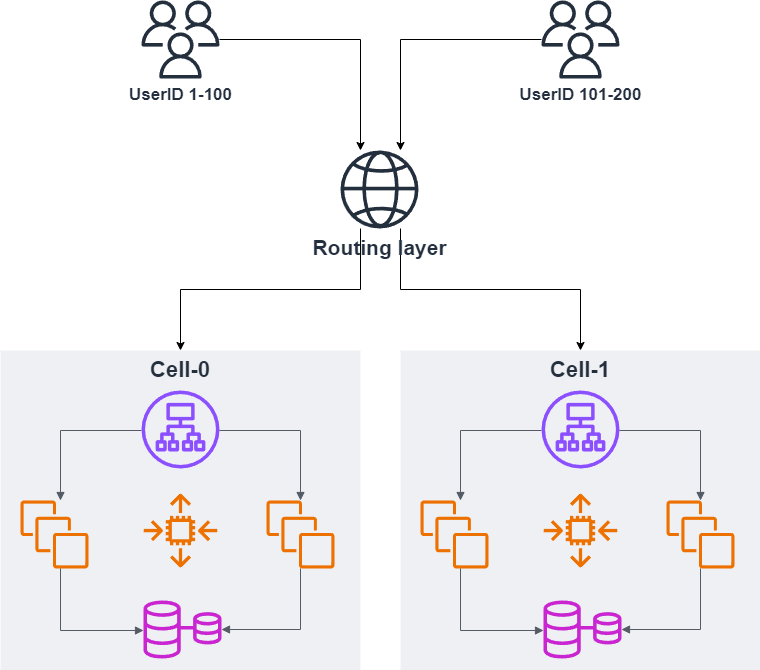
In this diagram, Routing layer looks like an inline proxy that receives all the requests and dispatch them based on their UserID. That’s one solution but sometime it can be an aside component such as CNAME e.g. user1.example.com => cell-0.example.com. With this solution, Routing layer isn’t a proxy but somehow control the routing rules. I’ll talk about more patterns in the last article of this series.
The most critical rule of Routing layer is keeping it as thin as possible. Because it’s impossible to split into cells, it can easily hit some scalability bottlenecks. Unlike the application itself, the purpose of Routing layer is just routing, so the implementation can be much simpler i.e. more scalable than each cell. It’s also a logical SPOF, so highly available design is important and deployments should be done carefully.
Cross-cell Control plane a.k.a. Cell migration
The last component of Cell-based Architecture is Cross-cell Control plane. The key difference from Cross-cell Data plane is that this component moves data across cells. So, this is also called “Cell migration“. In the example below, UserID 100 is migrated from Cell-0 to Cell-1. During the process, Cell migration touches not only both cells but also Routing layer to appropriately re-route the requests:

Cell migration is typically a workflow that carefully designed to keep data consistency during migration i.e. treating “Split brain“ problem. As you notice, it’s not a simple problem in distributed system, so Cell migration is the most advanced component of Cell-based Architecture and it’s not easy to implement correctly. Thus, it’s not a bad idea to start Cell migration with maintenance window e.g. while blocking all access by UserID 100, you copy all the data of UserID 100 to the new cell, then update Routing layer.
Why do you need to move data across cells? There are two reasons:
Cell balancing
Noisy neighbor isolation
Cell balancing is needed when some cells become too large or small. Although cell should be designed and operated under the manageable size, sometime you need to adjust such thresholds due to a new discovery. Or, you might just want to merge/split cells for better management, especially you adopt Cell-based Architecture after several years of operations.
Noisy neighbor is a user/resource that brings too high load to the cell e.g. DDoS attackers, celebrities, etc. Once you identify them, it is a good strategy to isolate them from the others for both parties. For example, DDoS attackers can be migrated to a special cell for only such users so that any normal users won’t be affected.
Anyway, the capability of Cell migration is a huge benefit and makes cell operations easier and safer. However, because of the complexity, it is recommended to implement Cell migration from day one.
Summary
In this post, I described three components of Cell-based Architecture: 1. Cell - A limited-scale and isolated full stack application, 2. Routing layer - A cross-cell data plane to route traffic to the appropriate cells, 3. Cell migration - A cross-cell control plane to move data across cells. By using Cells, you can handle scalability and availability problems we talked before pretty simply. However, Cells rises the other problems, such as separate endpoints, cell rebalancing. Both cross-cell components fill such gaps.
What’s next
You’ve learned the core concept of Cell-based Architecture here. The next topic is when it’s needed. The two problems - scalability and availability - are ubiquitous but I’m going to apply them for several use cases so that you can understand why they are the issues and Cell-based Architecture is needed there.

Thank you for reading. If you’re interested in this series, please hit the “Like“ button and share this to any social media. I would be motivated more! Also, subscribe this magazine to receive the upcoming posts for this series!
This is capable thanks to cloud and Infrastructure as Code.
Some quotas are per AWS account e.g. EC2 instances, Lambda concurrency. So, if you run multi cells in a single AWS account, your entire system could be capped by such quotas.